Synthetic data is artificially generated information created through algorithms and simulation models to replicate real-world data patterns. Augmented data involves enhancing existing datasets by applying transformations or adding variations to increase diversity and volume. Explore the nuances between synthetic and augmented data to understand their unique roles in advancing machine learning and AI development.
Why it is important
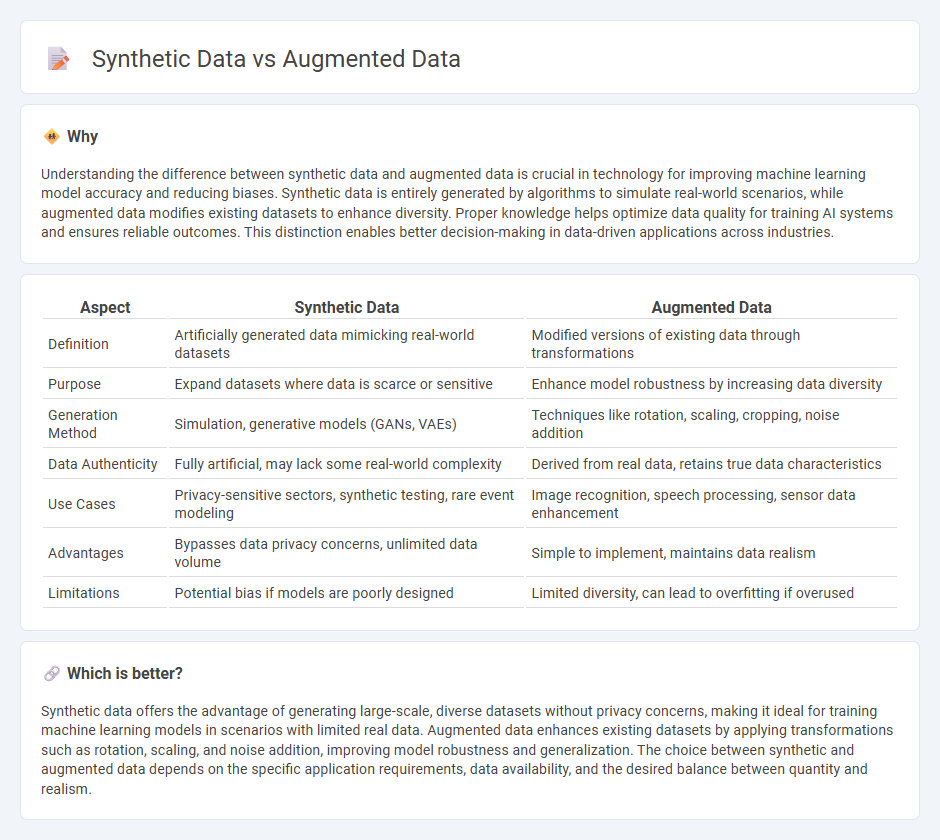
Understanding the difference between synthetic data and augmented data is crucial in technology for improving machine learning model accuracy and reducing biases. Synthetic data is entirely generated by algorithms to simulate real-world scenarios, while augmented data modifies existing datasets to enhance diversity. Proper knowledge helps optimize data quality for training AI systems and ensures reliable outcomes. This distinction enables better decision-making in data-driven applications across industries.
Comparison Table
| Aspect | Synthetic Data | Augmented Data |
|---|---|---|
| Definition | Artificially generated data mimicking real-world datasets | Modified versions of existing data through transformations |
| Purpose | Expand datasets where data is scarce or sensitive | Enhance model robustness by increasing data diversity |
| Generation Method | Simulation, generative models (GANs, VAEs) | Techniques like rotation, scaling, cropping, noise addition |
| Data Authenticity | Fully artificial, may lack some real-world complexity | Derived from real data, retains true data characteristics |
| Use Cases | Privacy-sensitive sectors, synthetic testing, rare event modeling | Image recognition, speech processing, sensor data enhancement |
| Advantages | Bypasses data privacy concerns, unlimited data volume | Simple to implement, maintains data realism |
| Limitations | Potential bias if models are poorly designed | Limited diversity, can lead to overfitting if overused |
Which is better?
Synthetic data offers the advantage of generating large-scale, diverse datasets without privacy concerns, making it ideal for training machine learning models in scenarios with limited real data. Augmented data enhances existing datasets by applying transformations such as rotation, scaling, and noise addition, improving model robustness and generalization. The choice between synthetic and augmented data depends on the specific application requirements, data availability, and the desired balance between quantity and realism.
Connection
Synthetic data and augmented data are interrelated through their roles in enhancing machine learning model training by expanding dataset diversity and volume. Synthetic data is artificially generated to mimic real-world data patterns, while augmented data involves transforming existing data through techniques like rotation, scaling, or noise addition to create variations. Both approaches mitigate issues of data scarcity and privacy constraints in technology-driven applications such as computer vision and natural language processing.
Key Terms
Data Augmentation
Data augmentation enhances machine learning model performance by creating diverse training samples through transformations like cropping, rotating, and scaling of existing real-world data, maintaining the dataset's inherent features. Synthetic data, generated entirely by algorithms or simulations, aims to expand datasets when real data is scarce but may lack some authentic variability. Explore more to understand how data augmentation techniques can effectively improve model robustness and accuracy.
Artificial Data Generation
Augmented data involves transforming existing datasets through techniques such as rotation, scaling, or noise addition to enhance model training diversity, while synthetic data is entirely generated from scratch using algorithms like GANs or simulation models to mimic real-world scenarios. Artificial data generation plays a crucial role in overcoming data scarcity, preserving privacy, and improving AI model robustness by providing scalable and customizable datasets. Explore detailed insights on how artificial data generation methods optimize AI performance and address real-world challenges.
Real-World Data
Augmented data enhances real-world data by applying transformations such as rotation, scaling, and noise addition to existing samples, improving model robustness while preserving original data characteristics. Synthetic data is entirely generated by algorithms or simulation models, offering scalable and privacy-preserving alternatives but may lack the nuanced variability of genuine real-world data. Explore how integrating augmented and synthetic data can optimize machine learning results in real-world applications.
Source and External Links
What is data augmentation? - IBM - Data augmentation generates new data samples by modifying existing data to improve machine learning model optimization and generalization.
A Complete Guide to Data Augmentation | DataCamp - Data augmentation increases the training set by creating modified copies of datasets, enhancing model performance and preventing overfitting.
What is Data Augmentation? - AWS - Data augmentation involves generating new data from existing data to improve machine learning model performance across various industries.