Self-supervised learning leverages unlabeled data by generating its own supervision signals, enabling models to learn useful representations without extensive labeled datasets. Transfer learning applies knowledge gained from a pre-trained model on a large dataset to improve performance on a related but different task with limited data availability. Explore more to understand how these approaches revolutionize machine learning efficiency and accuracy.
Why it is important
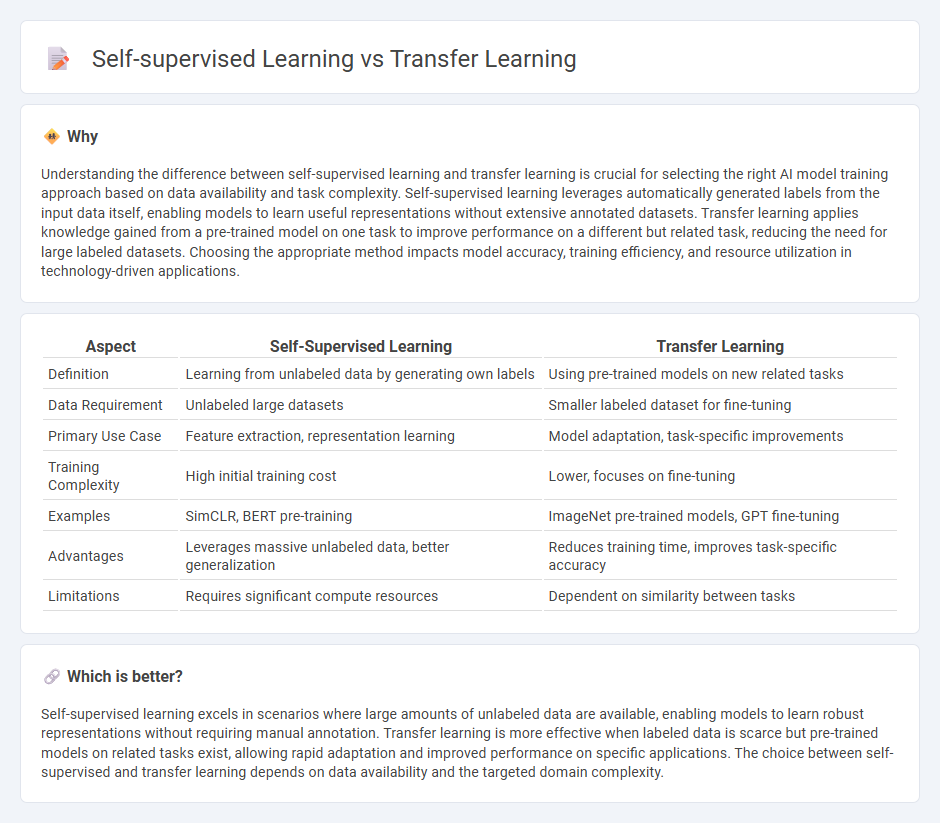
Understanding the difference between self-supervised learning and transfer learning is crucial for selecting the right AI model training approach based on data availability and task complexity. Self-supervised learning leverages automatically generated labels from the input data itself, enabling models to learn useful representations without extensive annotated datasets. Transfer learning applies knowledge gained from a pre-trained model on one task to improve performance on a different but related task, reducing the need for large labeled datasets. Choosing the appropriate method impacts model accuracy, training efficiency, and resource utilization in technology-driven applications.
Comparison Table
| Aspect | Self-Supervised Learning | Transfer Learning |
|---|---|---|
| Definition | Learning from unlabeled data by generating own labels | Using pre-trained models on new related tasks |
| Data Requirement | Unlabeled large datasets | Smaller labeled dataset for fine-tuning |
| Primary Use Case | Feature extraction, representation learning | Model adaptation, task-specific improvements |
| Training Complexity | High initial training cost | Lower, focuses on fine-tuning |
| Examples | SimCLR, BERT pre-training | ImageNet pre-trained models, GPT fine-tuning |
| Advantages | Leverages massive unlabeled data, better generalization | Reduces training time, improves task-specific accuracy |
| Limitations | Requires significant compute resources | Dependent on similarity between tasks |
Which is better?
Self-supervised learning excels in scenarios where large amounts of unlabeled data are available, enabling models to learn robust representations without requiring manual annotation. Transfer learning is more effective when labeled data is scarce but pre-trained models on related tasks exist, allowing rapid adaptation and improved performance on specific applications. The choice between self-supervised and transfer learning depends on data availability and the targeted domain complexity.
Connection
Self-supervised learning generates data representations by leveraging unlabeled data through pretext tasks, which enhances feature extraction and reduces the need for manual labeling. Transfer learning utilizes these pretrained models from self-supervised learning to adapt knowledge efficiently across related tasks or domains, improving performance with limited labeled data. This synergy accelerates model training and boosts accuracy in applications like natural language processing and computer vision.
Key Terms
Pre-trained Models
Pre-trained models in transfer learning leverage labeled datasets to fine-tune on specific tasks, significantly reducing training time and improving accuracy in domains with limited data. Self-supervised learning, by contrast, generates its own labels from unlabeled data, enabling models to learn robust feature representations without manual annotation. Explore how these approaches impact model performance and scalability across various AI applications.
Labeled Data
Transfer learning significantly reduces reliance on large labeled datasets by leveraging pre-trained models on related tasks, effectively improving performance with fewer labeled examples. Self-supervised learning further minimizes the need for labeled data by exploiting intrinsic data structures to generate supervisory signals, enabling models to learn useful representations from unlabeled data. Discover how these paradigms uniquely optimize labeled data usage and enhance machine learning efficiency.
Feature Representation
Transfer learning leverages pre-trained models on large datasets to improve feature representation for downstream tasks, enhancing model accuracy and reducing training time. Self-supervised learning creates robust feature embeddings by predicting parts of the input data itself, enabling effective learning from unlabeled data. Explore the strengths and applications of both methods to optimize feature representation in machine learning models.
Source and External Links
What is transfer learning? - IBM - Transfer learning is a machine learning technique where knowledge gained in one task or dataset is used to improve model performance on a related but different task or dataset, particularly useful in deep learning to overcome data scarcity and retraining from scratch.
What Is Transfer Learning? A Guide for Deep Learning | Built In - Transfer learning reuses a pre-trained model on a new, related problem to exploit learned patterns and improve generalization, especially in deep learning tasks like computer vision and natural language processing with limited data.
What is Transfer Learning? - AWS - Transfer learning fine-tunes a pre-trained machine learning model for a new related task, offering benefits such as faster training, reduced data requirements, improved performance, and increased accessibility for various applications.