Edge inference processes data locally on devices, reducing latency and enhancing privacy by minimizing data transfer to central servers. Centralized inference relies on powerful cloud servers to analyze data, offering scalability and easier model updates but potentially increasing response time and data security risks. Discover more about how these approaches impact AI performance and application deployment.
Why it is important
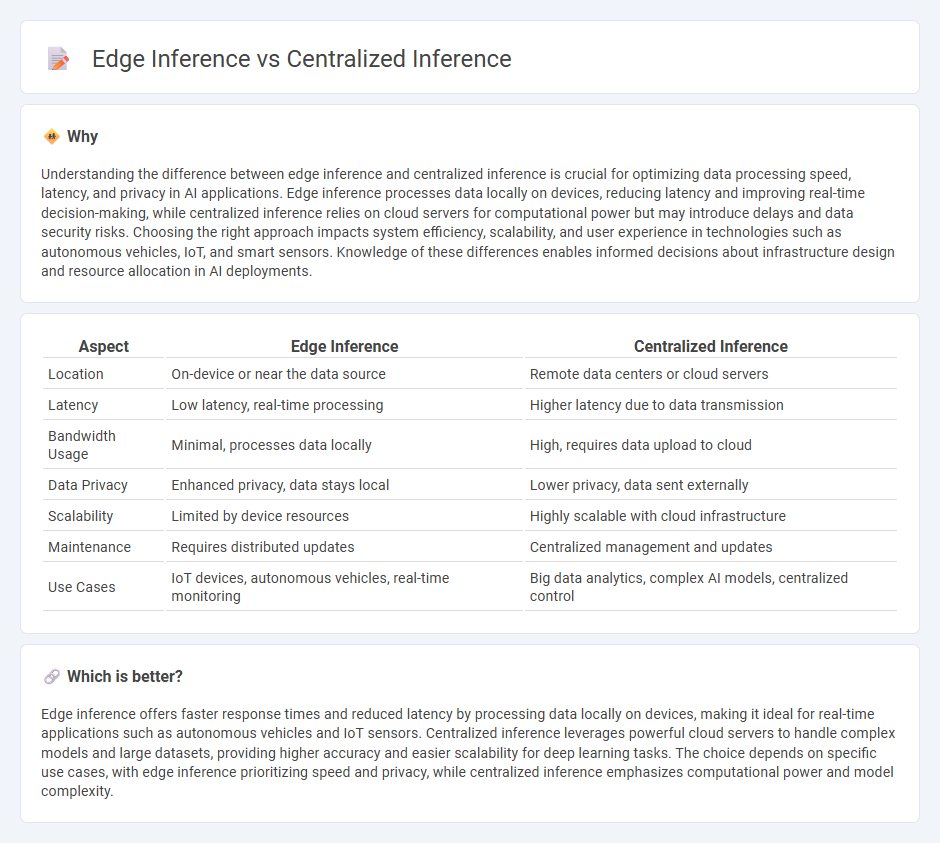
Understanding the difference between edge inference and centralized inference is crucial for optimizing data processing speed, latency, and privacy in AI applications. Edge inference processes data locally on devices, reducing latency and improving real-time decision-making, while centralized inference relies on cloud servers for computational power but may introduce delays and data security risks. Choosing the right approach impacts system efficiency, scalability, and user experience in technologies such as autonomous vehicles, IoT, and smart sensors. Knowledge of these differences enables informed decisions about infrastructure design and resource allocation in AI deployments.
Comparison Table
| Aspect | Edge Inference | Centralized Inference |
|---|---|---|
| Location | On-device or near the data source | Remote data centers or cloud servers |
| Latency | Low latency, real-time processing | Higher latency due to data transmission |
| Bandwidth Usage | Minimal, processes data locally | High, requires data upload to cloud |
| Data Privacy | Enhanced privacy, data stays local | Lower privacy, data sent externally |
| Scalability | Limited by device resources | Highly scalable with cloud infrastructure |
| Maintenance | Requires distributed updates | Centralized management and updates |
| Use Cases | IoT devices, autonomous vehicles, real-time monitoring | Big data analytics, complex AI models, centralized control |
Which is better?
Edge inference offers faster response times and reduced latency by processing data locally on devices, making it ideal for real-time applications such as autonomous vehicles and IoT sensors. Centralized inference leverages powerful cloud servers to handle complex models and large datasets, providing higher accuracy and easier scalability for deep learning tasks. The choice depends on specific use cases, with edge inference prioritizing speed and privacy, while centralized inference emphasizes computational power and model complexity.
Connection
Edge inference processes data locally on edge devices, reducing latency and bandwidth usage by performing real-time analytics near the data source. Centralized inference leverages powerful cloud servers to aggregate data from multiple edge devices, enabling complex model training and large-scale analytics. The connection between edge and centralized inference lies in a hybrid architecture that balances local processing for immediate insights with centralized analysis for comprehensive intelligence and model updates.
Key Terms
Latency
Centralized inference relies on cloud servers to process data, often resulting in higher latency due to data transmission times and network congestion. Edge inference performs data processing locally on devices or edge nodes, significantly reducing latency by minimizing the need for data travel. Explore the benefits and trade-offs of these approaches to optimize system responsiveness and efficiency.
Bandwidth
Centralized inference relies on transmitting raw data to powerful cloud servers, which demands high bandwidth and can introduce latency issues. Edge inference processes data locally on devices, significantly reducing bandwidth usage and enabling real-time decision-making. Explore more about the trade-offs between centralized and edge inference to optimize your network performance.
Data Privacy
Centralized inference processes data on cloud servers, which can expose sensitive information during transmission, posing privacy risks. Edge inference conducts data analysis locally on devices, minimizing data transfer and reducing vulnerability to breaches. Learn more about how edge inference enhances data privacy in AI applications.
Source and External Links
The Case for Centralized AI Model Inference Serving - Centralized inference serving optimizes deep learning execution by reducing resource contention and improving system utilization through a dedicated server.
Understanding Inference Workload Patterns and Requirements for Private Cloud AI - Centralized inference runs in private data centers, leveraging hardware acceleration and orchestration tools for scalable, accurate, and controlled model deployment.
AI Inference Tips: Best Practices and Deployment - Centralized management enables unified control and dynamic scaling of AI inference workloads across cloud and on-premises environments.