Self-supervised learning leverages unlabeled data by generating pseudo-labels from the data itself, enabling models to learn representations without manual annotation. Supervised learning relies on labeled datasets where input-output pairs guide the model to minimize prediction errors through explicit feedback. Explore more about how these paradigms drive innovation in AI and machine learning.
Why it is important
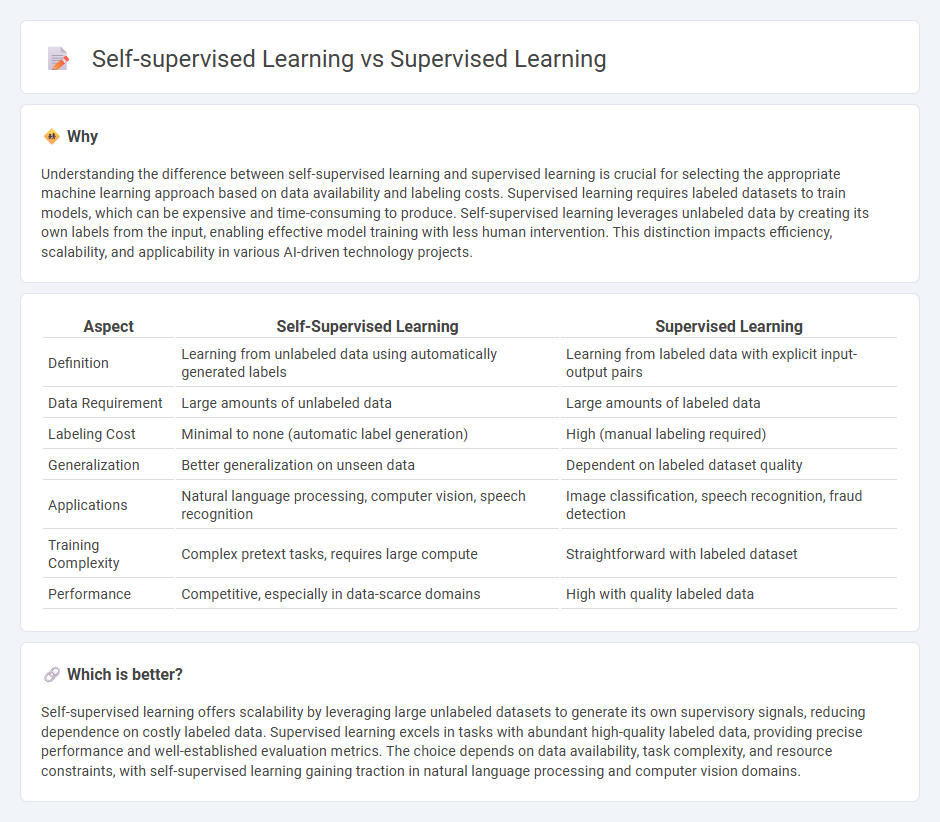
Understanding the difference between self-supervised learning and supervised learning is crucial for selecting the appropriate machine learning approach based on data availability and labeling costs. Supervised learning requires labeled datasets to train models, which can be expensive and time-consuming to produce. Self-supervised learning leverages unlabeled data by creating its own labels from the input, enabling effective model training with less human intervention. This distinction impacts efficiency, scalability, and applicability in various AI-driven technology projects.
Comparison Table
| Aspect | Self-Supervised Learning | Supervised Learning |
|---|---|---|
| Definition | Learning from unlabeled data using automatically generated labels | Learning from labeled data with explicit input-output pairs |
| Data Requirement | Large amounts of unlabeled data | Large amounts of labeled data |
| Labeling Cost | Minimal to none (automatic label generation) | High (manual labeling required) |
| Generalization | Better generalization on unseen data | Dependent on labeled dataset quality |
| Applications | Natural language processing, computer vision, speech recognition | Image classification, speech recognition, fraud detection |
| Training Complexity | Complex pretext tasks, requires large compute | Straightforward with labeled dataset |
| Performance | Competitive, especially in data-scarce domains | High with quality labeled data |
Which is better?
Self-supervised learning offers scalability by leveraging large unlabeled datasets to generate its own supervisory signals, reducing dependence on costly labeled data. Supervised learning excels in tasks with abundant high-quality labeled data, providing precise performance and well-established evaluation metrics. The choice depends on data availability, task complexity, and resource constraints, with self-supervised learning gaining traction in natural language processing and computer vision domains.
Connection
Self-supervised learning and supervised learning are interconnected through their foundational objective of improving model accuracy using labeled data, but self-supervised learning generates its own labels from unlabeled data to pretrain models. This approach leverages large datasets without manual annotation, creating representations that enhance supervised learning's performance on specific tasks. Consequently, self-supervised learning acts as a precursor, refining feature extraction before fine-tuning with labeled data in supervised learning frameworks.
Key Terms
Labeled Data
Supervised learning relies heavily on labeled data where each input is paired with a corresponding output, enabling precise model training through direct feedback. Self-supervised learning leverages unlabeled data by creating surrogate tasks that generate labels automatically from the data itself, reducing the dependence on manual annotation. Explore the differences in data requirements and applications to better understand which method suits your machine learning projects.
Feature Extraction
Supervised learning relies on labeled datasets to train models, enabling precise feature extraction by mapping inputs to known outputs, which enhances tasks like image classification and sentiment analysis. Self-supervised learning leverages unlabeled data, creating auxiliary tasks that help models learn robust feature representations without explicit labels, significantly improving transferability in applications such as natural language processing and computer vision. Explore the nuances of feature extraction methods in both learning paradigms to optimize your machine learning projects.
Representation Learning
Supervised learning relies on labeled datasets to train models, optimizing representation learning by minimizing prediction errors directly tied to explicit labels. Self-supervised learning extracts meaningful representations from unlabeled data through pretext tasks, leveraging intrinsic data structures to improve feature learning without manual annotations. Explore the latest advances in representation learning to discover how these methods transform model efficiency and accuracy.
Source and External Links
What Is Supervised Learning? | IBM - Supervised learning is a machine learning technique that uses human-labeled input and output datasets to train AI models to predict accurate outputs on unseen data by learning relationships between inputs and outputs.
Supervised Machine Learning | GeeksforGeeks - Supervised learning involves training models on labeled data with correct outputs, enabling them to learn to minimize errors and make accurate predictions on new data in tasks such as classification and regression.
What is Supervised Learning? | Google Cloud - It is a category of machine learning that uses labeled datasets to teach algorithms to recognize patterns and predict outcomes, widely applied across industries like healthcare and finance.