Multimodal AI integrates data from diverse sources such as text, images, and audio to enable machines to understand context more comprehensively, unlike supervised learning which relies solely on labeled datasets for specific tasks. By leveraging multiple modalities, multimodal AI enhances performance in complex applications like natural language understanding, computer vision, and speech recognition. Explore the latest advancements in multimodal AI to see how it revolutionizes traditional supervised learning methods.
Why it is important
Understanding the difference between multimodal AI and supervised learning is crucial for leveraging technology efficiently in industries like healthcare and autonomous driving. Multimodal AI integrates data from various sources such as images, text, and audio to improve decision-making, while supervised learning relies on labeled data to train models for specific tasks. Knowing these distinctions enables developers to select appropriate algorithms that enhance accuracy and functionality in AI applications. This knowledge drives innovations and optimizes resource allocation in AI system development.
Comparison Table
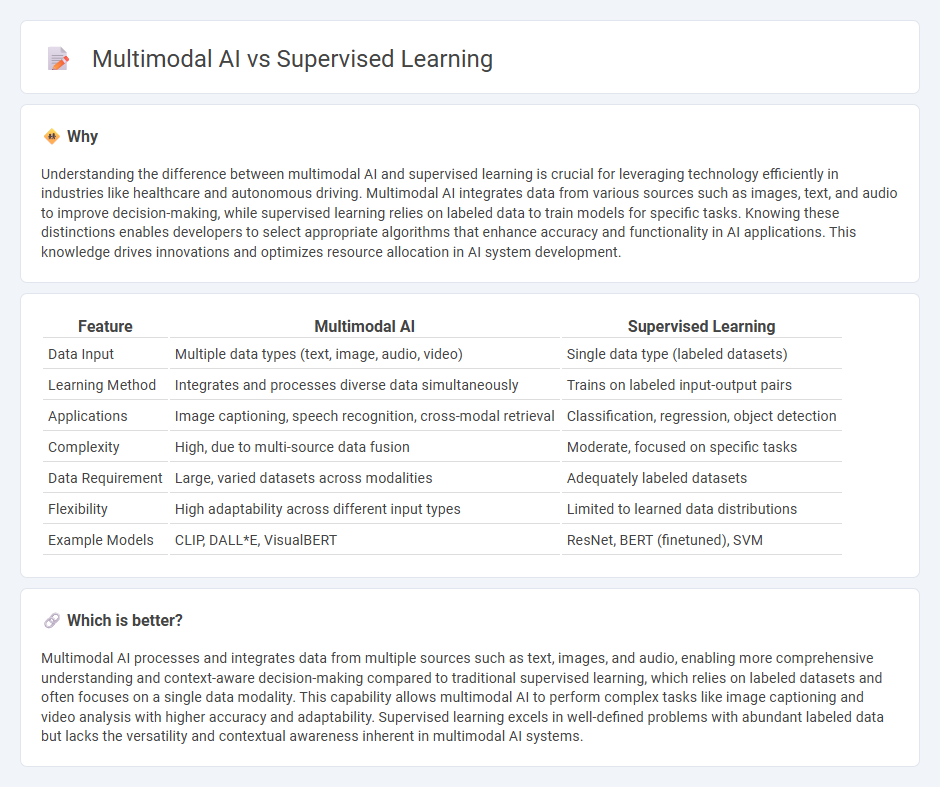
| Feature | Multimodal AI | Supervised Learning |
|---|---|---|
| Data Input | Multiple data types (text, image, audio, video) | Single data type (labeled datasets) |
| Learning Method | Integrates and processes diverse data simultaneously | Trains on labeled input-output pairs |
| Applications | Image captioning, speech recognition, cross-modal retrieval | Classification, regression, object detection |
| Complexity | High, due to multi-source data fusion | Moderate, focused on specific tasks |
| Data Requirement | Large, varied datasets across modalities | Adequately labeled datasets |
| Flexibility | High adaptability across different input types | Limited to learned data distributions |
| Example Models | CLIP, DALL*E, VisualBERT | ResNet, BERT (finetuned), SVM |
Which is better?
Multimodal AI processes and integrates data from multiple sources such as text, images, and audio, enabling more comprehensive understanding and context-aware decision-making compared to traditional supervised learning, which relies on labeled datasets and often focuses on a single data modality. This capability allows multimodal AI to perform complex tasks like image captioning and video analysis with higher accuracy and adaptability. Supervised learning excels in well-defined problems with abundant labeled data but lacks the versatility and contextual awareness inherent in multimodal AI systems.
Connection
Multimodal AI integrates data from various sensory inputs--such as text, images, and audio--to enhance machine understanding, relying on supervised learning to accurately label and map these diverse data types during training. Supervised learning employs annotated datasets to teach models how to recognize patterns across multiple modalities, improving the AI's ability to interpret complex information in real-world applications. This synergy enables more robust performance in tasks like image captioning, speech recognition, and natural language understanding by leveraging cross-modal correlations.
Key Terms
Labels
Supervised learning relies heavily on labeled datasets where each input is paired with a corresponding output, enabling models to learn explicit mappings for prediction tasks. Multimodal AI processes and integrates diverse data types such as text, images, and audio, often requiring complex labeling strategies to align different modalities effectively. Explore how labeling techniques impact performance and scalability in both supervised learning and multimodal AI to enhance your understanding.
Modality
Supervised learning primarily relies on labeled data within a specific modality, such as images or text, to train algorithms for accurate predictions. Multimodal AI integrates multiple data modalities like visual, textual, and auditory inputs, enhancing contextual understanding and decision-making capabilities. Explore how combining modalities drives innovation in AI applications for deeper insights and improved performance.
Fusion
Supervised learning traditionally relies on labeled datasets to train models on specific tasks, whereas multimodal AI integrates and processes data from multiple sources such as text, images, and audio to enhance understanding and performance. Fusion methods in multimodal AI combine features at different levels--early, intermediate, and late fusion--to improve prediction accuracy and robustness compared to unimodal approaches in supervised learning. Explore how advanced fusion techniques are transforming multimodal AI and enabling more sophisticated, context-aware systems.
Source and External Links
What Is Supervised Learning? | IBM - Supervised learning is a machine learning technique that uses human-labeled input and output datasets to train AI models to predict correct outputs on new data by learning the relationships between inputs and outputs.
Supervised Machine Learning | GeeksforGeeks - It is a fundamental ML approach where models are trained on labeled data, learning from example inputs and their correct outputs to make accurate predictions on unseen data.
What is Supervised Learning? | Google Cloud - Supervised learning uses labeled datasets to train algorithms that predict outcomes by analyzing feature-label relationships, enabling applications across industries like healthcare and finance.