Multimodal AI integrates multiple data types such as text, images, and audio to enhance machine understanding and interaction, enabling more versatile applications across industries. Generative AI focuses on creating new content, including text, images, or music, by learning patterns from vast datasets, driving innovations in creative fields. Explore more to understand how these advanced technologies are transforming the digital landscape.
Why it is important
Understanding the difference between multimodal AI and generative AI is crucial for leveraging their distinct capabilities in technology applications. Multimodal AI processes and integrates multiple data types like text, images, and audio to enhance decision-making and user interaction. Generative AI focuses on creating new content such as text, images, or music based on learned patterns, driving innovation in creative industries. Recognizing these differences enables more effective deployment of AI technologies tailored to specific business and technological needs.
Comparison Table
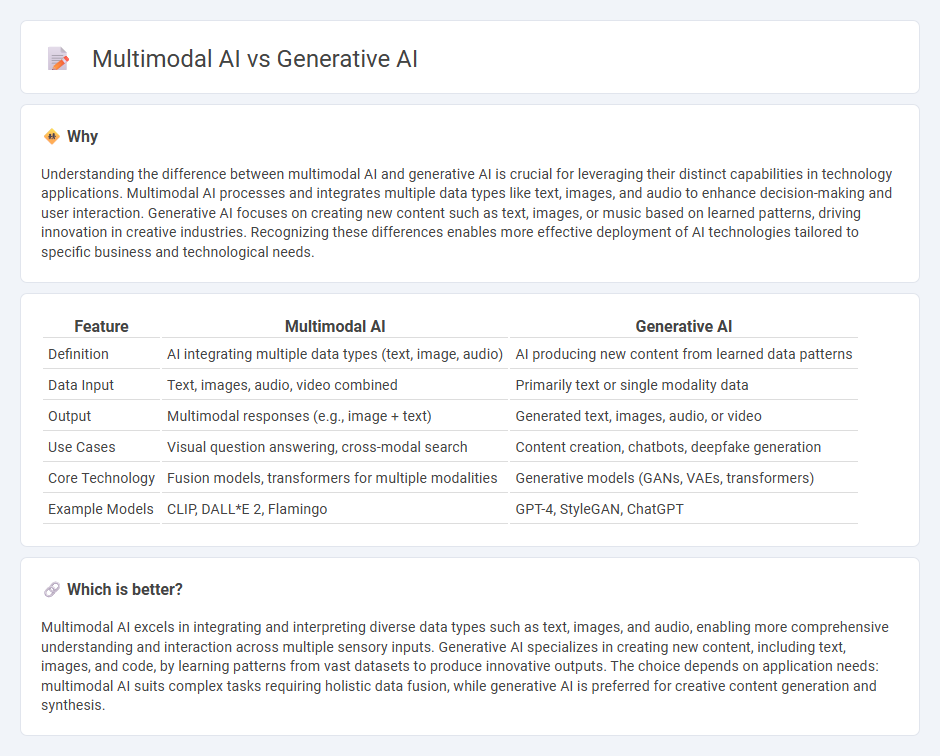
| Feature | Multimodal AI | Generative AI |
|---|---|---|
| Definition | AI integrating multiple data types (text, image, audio) | AI producing new content from learned data patterns |
| Data Input | Text, images, audio, video combined | Primarily text or single modality data |
| Output | Multimodal responses (e.g., image + text) | Generated text, images, audio, or video |
| Use Cases | Visual question answering, cross-modal search | Content creation, chatbots, deepfake generation |
| Core Technology | Fusion models, transformers for multiple modalities | Generative models (GANs, VAEs, transformers) |
| Example Models | CLIP, DALL*E 2, Flamingo | GPT-4, StyleGAN, ChatGPT |
Which is better?
Multimodal AI excels in integrating and interpreting diverse data types such as text, images, and audio, enabling more comprehensive understanding and interaction across multiple sensory inputs. Generative AI specializes in creating new content, including text, images, and code, by learning patterns from vast datasets to produce innovative outputs. The choice depends on application needs: multimodal AI suits complex tasks requiring holistic data fusion, while generative AI is preferred for creative content generation and synthesis.
Connection
Multimodal AI integrates various data types such as text, images, and audio to enhance machine understanding, while generative AI focuses on creating new content from learned patterns. These technologies converge when generative AI models utilize multimodal inputs to produce diverse outputs, improving creativity and contextual relevance. This synergy accelerates advancements in natural language processing, computer vision, and interactive applications.
Key Terms
Content Generation
Generative AI specializes in producing text, images, music, and videos using deep learning models such as GPT, DALL-E, and MusicLM, enhancing creative content generation for marketing, entertainment, and design. Multimodal AI integrates multiple data types like text, images, and audio simultaneously, improving contextual understanding and enabling richer, more interactive content experiences across platforms. Explore the evolving capabilities and applications of these AI technologies to revolutionize your content creation strategies.
Multi-Input Fusion
Generative AI primarily creates content from a single type of data, such as text or images, while multimodal AI integrates multiple input types like text, images, and audio to enhance context understanding and output quality. Multi-input fusion in multimodal AI enables more comprehensive data analysis by combining diverse sensory inputs, improving decision-making accuracy and user interaction. Explore the latest advancements and applications of multi-input fusion in AI to see how this paradigm is revolutionizing machine learning.
Cross-Modal Understanding
Generative AI creates content such as text, images, or audio from learned patterns within a single modality, while multimodal AI integrates information across multiple data types to enhance cross-modal understanding. Cross-modal understanding enables AI to interpret and relate inputs like images and text simultaneously, improving tasks like image captioning and video analysis. Discover deeper insights into how these technologies shape AI's ability to process diverse data formats effectively.
Source and External Links
Generative AI Explained - This webpage explains that generative AI uses sophisticated algorithms to organize complex data sets to create new content, such as text, images, and audio, in response to queries or prompts.
Generative AI: What it is and why it matters - This article discusses how generative AI consumes existing data, learns from it, and generates new data with similar characteristics, such as text, images, videos, audio, and code.
What is Generative AI? - This webpage describes generative AI as a technology that can create original content like text, images, video, audio, or software code in response to user prompts or requests using deep learning models.