Vector databases excel in handling complex similarity searches for high-dimensional data such as images and natural language, optimizing machine learning and AI applications. Data warehouses specialize in structured data storage and analytics, supporting large-scale business intelligence and reporting with integrated ETL processes. Explore further to understand which technology best fits your data management needs.
Why it is important
Understanding the difference between vector databases and data warehouses is crucial for leveraging the right technology in big data analytics and machine learning applications. Vector databases specialize in storing and querying high-dimensional data like embeddings for AI tasks, while data warehouses are optimized for structured, relational data analysis and business intelligence. This distinction enables organizations to improve data processing efficiency and enhance decision-making accuracy. Selecting the appropriate system directly impacts performance, scalability, and the ability to extract meaningful insights from complex datasets.
Comparison Table
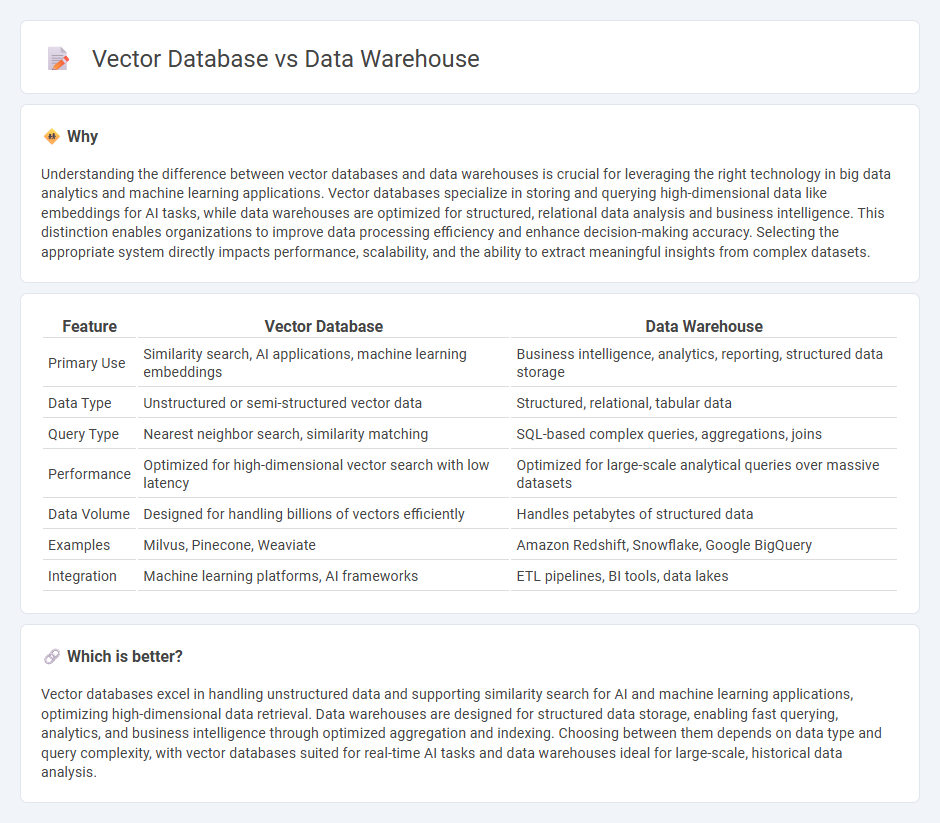
| Feature | Vector Database | Data Warehouse |
|---|---|---|
| Primary Use | Similarity search, AI applications, machine learning embeddings | Business intelligence, analytics, reporting, structured data storage |
| Data Type | Unstructured or semi-structured vector data | Structured, relational, tabular data |
| Query Type | Nearest neighbor search, similarity matching | SQL-based complex queries, aggregations, joins |
| Performance | Optimized for high-dimensional vector search with low latency | Optimized for large-scale analytical queries over massive datasets |
| Data Volume | Designed for handling billions of vectors efficiently | Handles petabytes of structured data |
| Examples | Milvus, Pinecone, Weaviate | Amazon Redshift, Snowflake, Google BigQuery |
| Integration | Machine learning platforms, AI frameworks | ETL pipelines, BI tools, data lakes |
Which is better?
Vector databases excel in handling unstructured data and supporting similarity search for AI and machine learning applications, optimizing high-dimensional data retrieval. Data warehouses are designed for structured data storage, enabling fast querying, analytics, and business intelligence through optimized aggregation and indexing. Choosing between them depends on data type and query complexity, with vector databases suited for real-time AI tasks and data warehouses ideal for large-scale, historical data analysis.
Connection
Vector databases enhance data warehouses by enabling efficient storage and retrieval of high-dimensional data, such as embeddings from machine learning models. Data warehouses aggregate structured data for analytics, while vector databases optimize similarity searches, crucial for AI-driven insights. Integrating both allows organizations to leverage comprehensive analytics alongside advanced vector-based search capabilities.
Key Terms
Structured Data vs. Unstructured Data
Data warehouses excel at managing structured data through organized schemas and SQL-based queries, enabling efficient analysis of transactional and historical information. Vector databases specialize in handling unstructured data by storing and querying high-dimensional vectors, supporting applications like image recognition, natural language processing, and recommendation systems. Explore how integrating both data storage technologies can enhance your organization's data strategy.
OLAP (Online Analytical Processing) vs. Similarity Search
Data warehouses are engineered for OLAP, enabling complex queries, aggregations, and multi-dimensional analysis across vast structured datasets to support business intelligence and reporting. Vector databases specialize in similarity search, leveraging high-dimensional vector representations for tasks like image recognition, natural language processing, and recommendation systems, optimizing retrieval of closely related data points. Explore the distinctive roles of data warehouses and vector databases to harness the right solution for analytical or similarity search needs.
Schema-on-Write vs. Embeddings
Data warehouses employ Schema-on-Write by structuring data during ingestion for fast, organized querying of relational data. Vector databases store embeddings--numerical representations of unstructured data--enabling efficient similarity searches for AI and machine learning applications. Explore how these technologies transform data management by understanding their fundamental differences and use cases.
Source and External Links
What is a Data Warehouse? - AWS - A data warehouse is a central repository of information from various sources designed to support fast querying and analysis for business intelligence, hosting data in tiers to optimize storage and query speed.
What is a Data Warehouse? | IBM - A data warehouse aggregates data from multiple sources into a centralized store to support analytics, BI, machine learning, and AI, and can handle large volumes of structured, semi-structured, or unstructured data, either on-premises or in the cloud.
Data warehouse - Wikipedia - A data warehouse is a system for reporting and data analysis, integrating data from disparate sources and organizing current and historical data to optimize analytics and decision-making through ETL or ELT workflows.