Synthetic media detection leverages advanced algorithms and machine learning models to identify manipulated or artificially generated content, ensuring authenticity in digital assets. Data augmentation enhances model training by artificially expanding datasets with transformed or synthesized samples, improving accuracy and robustness in detection systems. Explore how these technologies intersect to advance digital security and media integrity.
Why it is important
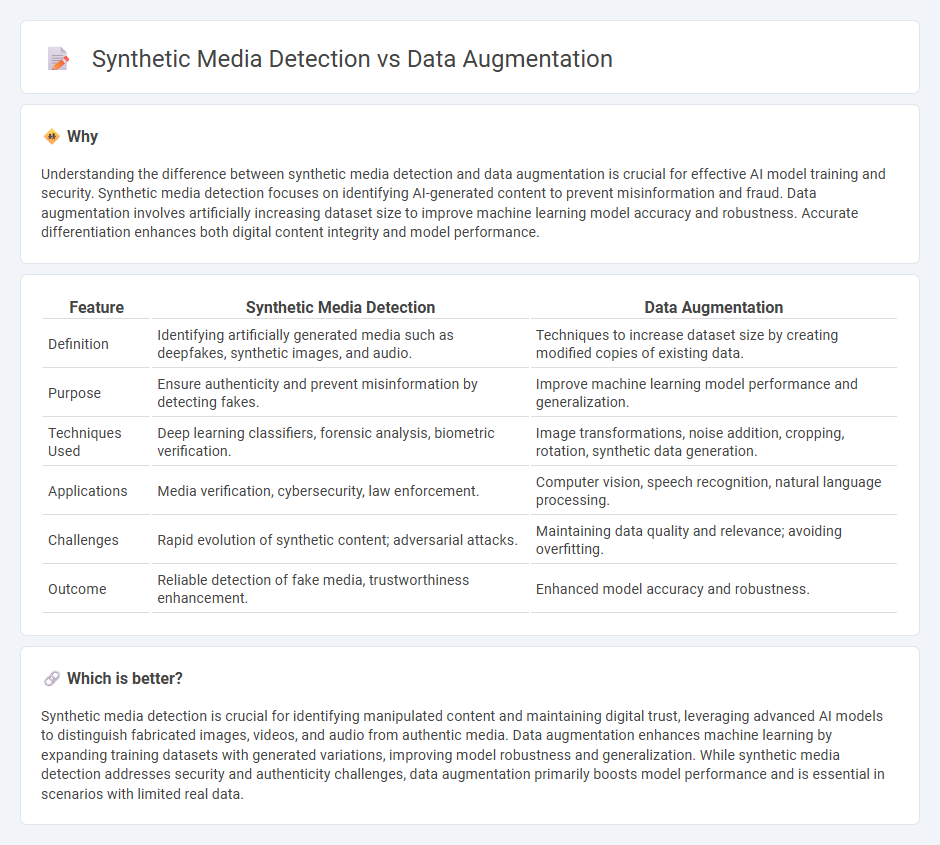
Understanding the difference between synthetic media detection and data augmentation is crucial for effective AI model training and security. Synthetic media detection focuses on identifying AI-generated content to prevent misinformation and fraud. Data augmentation involves artificially increasing dataset size to improve machine learning model accuracy and robustness. Accurate differentiation enhances both digital content integrity and model performance.
Comparison Table
| Feature | Synthetic Media Detection | Data Augmentation |
|---|---|---|
| Definition | Identifying artificially generated media such as deepfakes, synthetic images, and audio. | Techniques to increase dataset size by creating modified copies of existing data. |
| Purpose | Ensure authenticity and prevent misinformation by detecting fakes. | Improve machine learning model performance and generalization. |
| Techniques Used | Deep learning classifiers, forensic analysis, biometric verification. | Image transformations, noise addition, cropping, rotation, synthetic data generation. |
| Applications | Media verification, cybersecurity, law enforcement. | Computer vision, speech recognition, natural language processing. |
| Challenges | Rapid evolution of synthetic content; adversarial attacks. | Maintaining data quality and relevance; avoiding overfitting. |
| Outcome | Reliable detection of fake media, trustworthiness enhancement. | Enhanced model accuracy and robustness. |
Which is better?
Synthetic media detection is crucial for identifying manipulated content and maintaining digital trust, leveraging advanced AI models to distinguish fabricated images, videos, and audio from authentic media. Data augmentation enhances machine learning by expanding training datasets with generated variations, improving model robustness and generalization. While synthetic media detection addresses security and authenticity challenges, data augmentation primarily boosts model performance and is essential in scenarios with limited real data.
Connection
Synthetic media detection leverages data augmentation techniques to enhance model training by generating diverse and realistic synthetic datasets. These augmented datasets improve the robustness and accuracy of algorithms tasked with identifying deepfakes, manipulated images, and synthetic audio. Effective data augmentation addresses scarcity in labeled examples, enabling more precise detection of synthetic content in technology-driven digital environments.
Key Terms
Data augmentation
Data augmentation enhances machine learning models by generating diverse and representative training samples, improving robustness and generalization in tasks like image recognition and natural language processing. Techniques include transformations, noise injection, and algorithmic synthesis, addressing data scarcity and imbalance effectively. Explore how advanced data augmentation methods can revolutionize your AI model performance.
Deepfake detection
Data augmentation techniques enhance deepfake detection models by increasing the diversity of training datasets through transformations like rotation, scaling, and color adjustments, improving the robustness of neural networks against manipulated media. Synthetic media detection relies on advanced algorithms that analyze inconsistencies in facial expressions, blinking patterns, and pixel-level anomalies to identify deepfakes accurately. Explore cutting-edge research and tools to stay ahead in the evolving landscape of deepfake identification and prevention.
Generative Adversarial Networks (GANs)
Generative Adversarial Networks (GANs) play a pivotal role in both data augmentation and synthetic media detection by generating realistic datasets and identifying fabricated content respectively. Data augmentation leverages GANs to enhance training data diversity, improving model robustness and generalization across various domains such as computer vision and natural language processing. Explore the transformative impact of GANs on synthetic media technology and how they shape the future of AI-driven content reliability.
Source and External Links
What is Data Augmentation? - AWS - Data augmentation is the process of artificially generating new data from existing data by applying transformations, which helps improve the performance and generalization of machine learning models.
What is data augmentation? - IBM - Data augmentation involves creating modified copies of existing data to increase dataset size and diversity, improving model optimization and robustness while reducing overfitting.
A Complete Guide to Data Augmentation | DataCamp - Data augmentation is a technique for increasing the size and variety of a training set by generating modified versions of existing data, which is particularly important for preventing overfitting and improving model accuracy when real-world data is limited.