Generative audio leverages advanced machine learning algorithms to create new, original soundscapes and music compositions, enabling innovative audio experiences tailored to user preferences. Audio fingerprinting technology, on the other hand, analyzes unique digital patterns within audio signals to identify, categorize, and track content efficiently across platforms. Discover how these cutting-edge audio technologies are transforming media consumption and digital rights management.
Why it is important
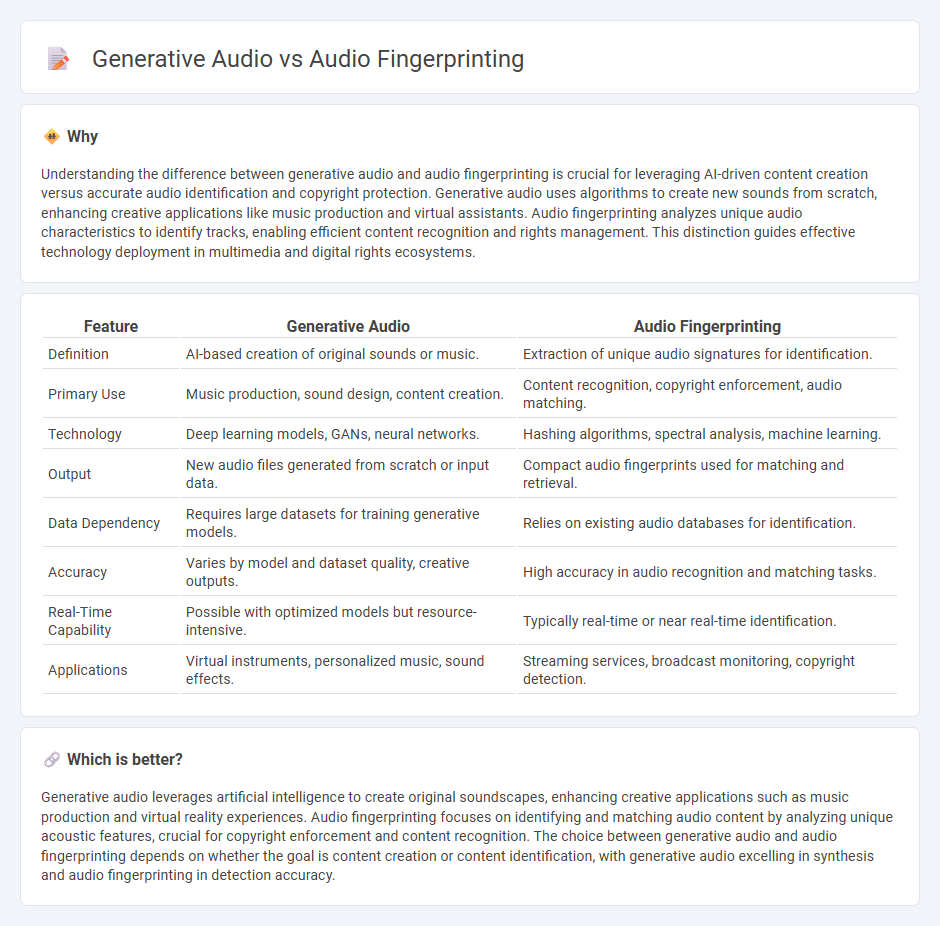
Understanding the difference between generative audio and audio fingerprinting is crucial for leveraging AI-driven content creation versus accurate audio identification and copyright protection. Generative audio uses algorithms to create new sounds from scratch, enhancing creative applications like music production and virtual assistants. Audio fingerprinting analyzes unique audio characteristics to identify tracks, enabling efficient content recognition and rights management. This distinction guides effective technology deployment in multimedia and digital rights ecosystems.
Comparison Table
| Feature | Generative Audio | Audio Fingerprinting |
|---|---|---|
| Definition | AI-based creation of original sounds or music. | Extraction of unique audio signatures for identification. |
| Primary Use | Music production, sound design, content creation. | Content recognition, copyright enforcement, audio matching. |
| Technology | Deep learning models, GANs, neural networks. | Hashing algorithms, spectral analysis, machine learning. |
| Output | New audio files generated from scratch or input data. | Compact audio fingerprints used for matching and retrieval. |
| Data Dependency | Requires large datasets for training generative models. | Relies on existing audio databases for identification. |
| Accuracy | Varies by model and dataset quality, creative outputs. | High accuracy in audio recognition and matching tasks. |
| Real-Time Capability | Possible with optimized models but resource-intensive. | Typically real-time or near real-time identification. |
| Applications | Virtual instruments, personalized music, sound effects. | Streaming services, broadcast monitoring, copyright detection. |
Which is better?
Generative audio leverages artificial intelligence to create original soundscapes, enhancing creative applications such as music production and virtual reality experiences. Audio fingerprinting focuses on identifying and matching audio content by analyzing unique acoustic features, crucial for copyright enforcement and content recognition. The choice between generative audio and audio fingerprinting depends on whether the goal is content creation or content identification, with generative audio excelling in synthesis and audio fingerprinting in detection accuracy.
Connection
Generative audio creates unique sound patterns that can be precisely identified using audio fingerprinting technology. Audio fingerprinting analyzes the acoustic features of generated sounds to enable accurate recognition and tracking across platforms. This synergy enhances content verification, copyright protection, and personalized audio experiences in digital media.
Key Terms
Feature Extraction
Audio fingerprinting relies on robust feature extraction techniques such as Mel-frequency cepstral coefficients (MFCCs) and spectral peaks to create compact, distinctive representations for accurate audio identification and synchronization. In contrast, generative audio models utilize deep learning-based feature extraction, including convolutional neural networks (CNNs) and transformers, to capture high-dimensional temporal and spectral patterns for audio synthesis and enhancement. Explore detailed comparisons and applications to better understand the impact of feature extraction in these audio processing domains.
Neural Synthesis
Audio fingerprinting identifies unique audio signatures for content recognition and copyright enforcement, using algorithms to analyze sound patterns swiftly. Neural synthesis, a cutting-edge generative audio technology, leverages neural networks to create realistic, high-quality soundscapes and voices by learning intricate audio features. Explore how advances in neural synthesis are transforming audio generation and content creation.
Content Identification
Audio fingerprinting efficiently identifies unique audio content by extracting compact digital summaries from sound waves, enabling rapid matching against vast databases. Generative audio creates new sounds or music using AI models, focusing on content creation rather than identification, which limits its use in content recognition. Explore detailed comparisons and applications of both technologies for advanced audio content identification.
Source and External Links
What is Audio Fingerprinting - This webpage provides a comprehensive guide to audio fingerprinting, explaining its concepts, applications in music recognition and copyright management, and how it works.
What is audio fingerprinting - This article explains the basics of audio fingerprinting, its different methods, and its applications in music identification and digital rights management.
Acoustic fingerprint - This Wikipedia page describes acoustic fingerprinting and its uses in identifying audio samples, managing sound effects, and monitoring media for copyright compliance.