Alternative data scraping involves extracting non-traditional financial information from diverse sources such as social media, satellite imagery, and transaction data to gain unique market insights. Web crawling systematically navigates web pages to collect structured data from public websites, commonly used for real-time pricing and financial news aggregation. Explore how leveraging these techniques can enhance investment strategies and decision-making in finance.
Why it is important
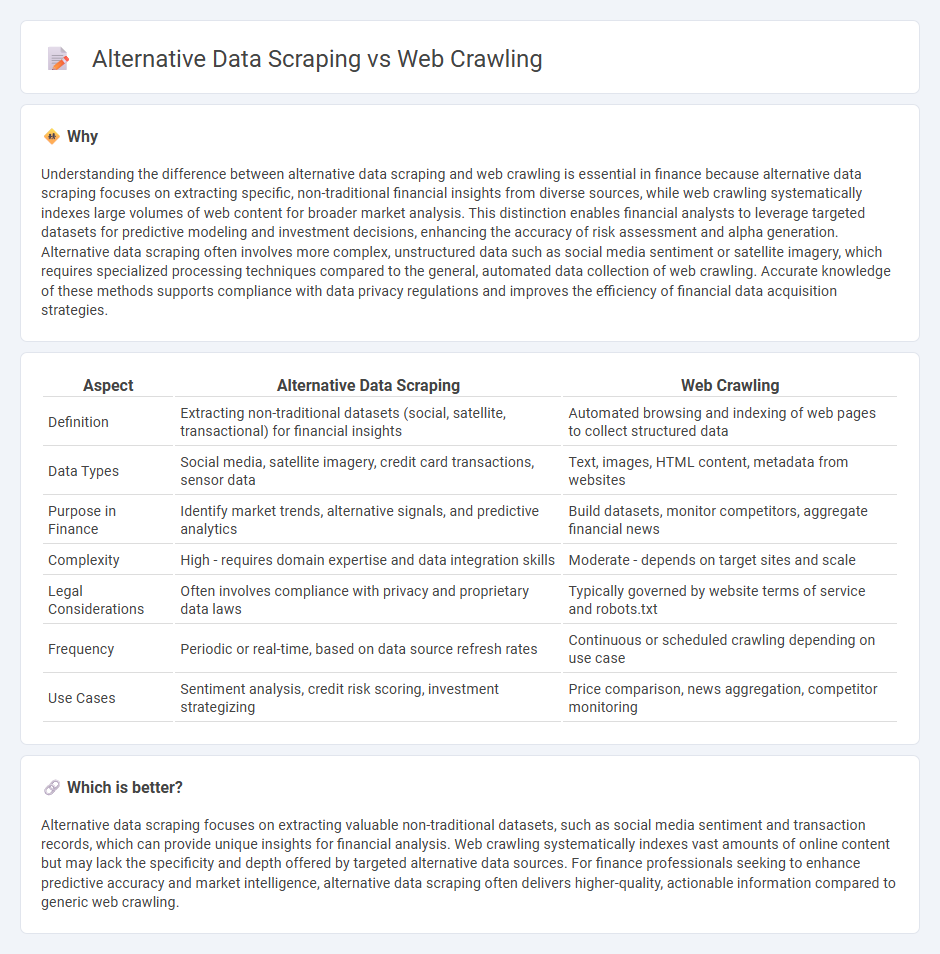
Understanding the difference between alternative data scraping and web crawling is essential in finance because alternative data scraping focuses on extracting specific, non-traditional financial insights from diverse sources, while web crawling systematically indexes large volumes of web content for broader market analysis. This distinction enables financial analysts to leverage targeted datasets for predictive modeling and investment decisions, enhancing the accuracy of risk assessment and alpha generation. Alternative data scraping often involves more complex, unstructured data such as social media sentiment or satellite imagery, which requires specialized processing techniques compared to the general, automated data collection of web crawling. Accurate knowledge of these methods supports compliance with data privacy regulations and improves the efficiency of financial data acquisition strategies.
Comparison Table
| Aspect | Alternative Data Scraping | Web Crawling |
|---|---|---|
| Definition | Extracting non-traditional datasets (social, satellite, transactional) for financial insights | Automated browsing and indexing of web pages to collect structured data |
| Data Types | Social media, satellite imagery, credit card transactions, sensor data | Text, images, HTML content, metadata from websites |
| Purpose in Finance | Identify market trends, alternative signals, and predictive analytics | Build datasets, monitor competitors, aggregate financial news |
| Complexity | High - requires domain expertise and data integration skills | Moderate - depends on target sites and scale |
| Legal Considerations | Often involves compliance with privacy and proprietary data laws | Typically governed by website terms of service and robots.txt |
| Frequency | Periodic or real-time, based on data source refresh rates | Continuous or scheduled crawling depending on use case |
| Use Cases | Sentiment analysis, credit risk scoring, investment strategizing | Price comparison, news aggregation, competitor monitoring |
Which is better?
Alternative data scraping focuses on extracting valuable non-traditional datasets, such as social media sentiment and transaction records, which can provide unique insights for financial analysis. Web crawling systematically indexes vast amounts of online content but may lack the specificity and depth offered by targeted alternative data sources. For finance professionals seeking to enhance predictive accuracy and market intelligence, alternative data scraping often delivers higher-quality, actionable information compared to generic web crawling.
Connection
Alternative data scraping and web crawling are interconnected processes essential for gathering diverse financial insights beyond traditional data sources. Web crawling automates the extraction of large volumes of structured and unstructured financial information from the internet, enabling alternative data scraping to collect unconventional datasets such as social media sentiment, satellite imagery, and transaction records. These technologies empower financial analysts and investors to enhance predictive models and improve decision-making by incorporating real-time, high-frequency alternative data.
Key Terms
Data Acquisition
Web crawling systematically indexes websites by following links to gather structured data at scale, ideal for building comprehensive search engines or market intelligence databases. Alternative data scraping targets specialized sources like social media, forums, or IoT devices to collect unique, real-time information not accessible through standard web crawling methods. Explore further to understand which data acquisition strategy suits your business objectives and data needs.
Unstructured Data
Web crawling collects large volumes of unstructured data by systematically browsing websites, capturing diverse content such as text, images, and metadata for analysis. Alternative data scraping targets niche, non-traditional datasets, often from social media, forums, or proprietary sources, offering unique insights beyond conventional web crawling. Explore deeper techniques and benefits of unstructured data extraction to enhance your data strategy.
Real-Time Analytics
Web crawling systematically indexes vast web content by following hyperlinks, enabling comprehensive data collection over time but often with delays. Alternative data scraping targets specific data sources such as social media, APIs, or sensor feeds, providing real-time data streams crucial for immediate analytics and decision-making. Explore how integrating these methods can optimize real-time analytics for dynamic market insights.
Source and External Links
What Is a Web Crawler? - A web crawler is an automated program that systematically searches and indexes content on websites, primarily for search engines.
How A Web Crawler Works - Web crawlers are computer programs that scan the web by following internal links, allowing them to index website content for search engines.
Web Crawler - Wikipedia - A web crawler, also known as a spider or spiderbot, is an internet bot used to browse and index the World Wide Web systematically for search engines and other services.