Liquid neural networks represent a dynamic approach to artificial intelligence, offering adaptability by continuously updating their internal states in response to changing inputs. Reservoir computing, by contrast, utilizes a fixed, random network (the reservoir) to transform inputs into high-dimensional representations, simplifying training processes. Explore the nuanced differences and applications of these innovative neural computing techniques to enhance your understanding of cutting-edge AI.
Why it is important
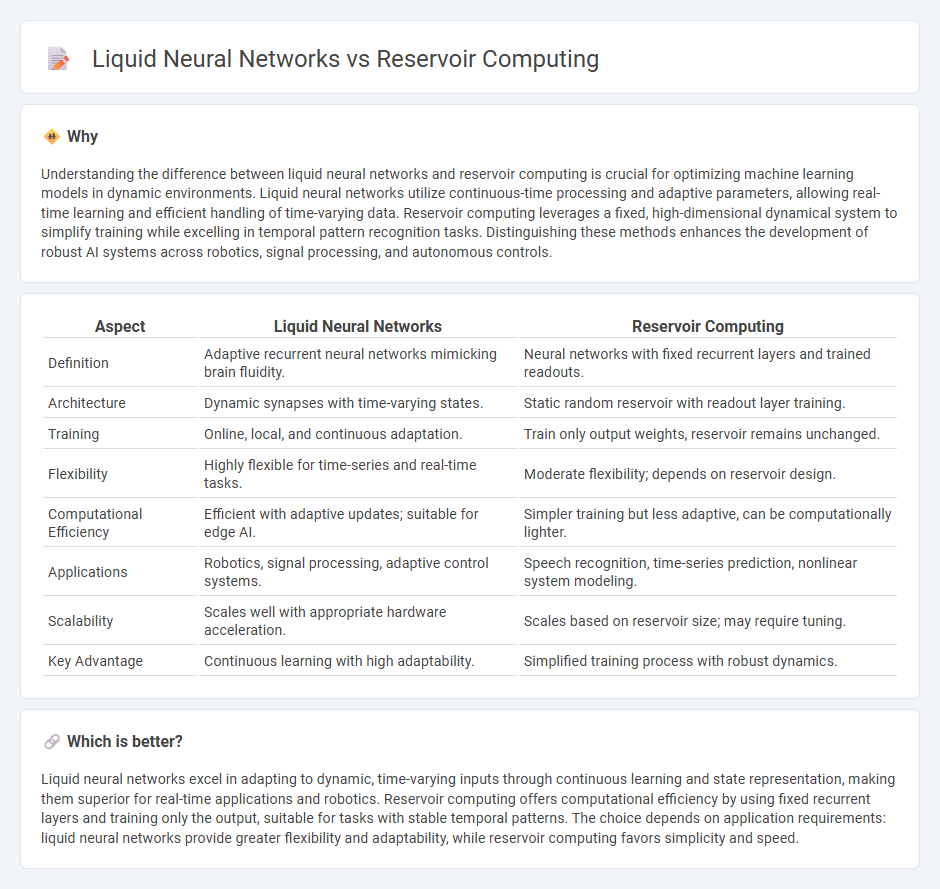
Understanding the difference between liquid neural networks and reservoir computing is crucial for optimizing machine learning models in dynamic environments. Liquid neural networks utilize continuous-time processing and adaptive parameters, allowing real-time learning and efficient handling of time-varying data. Reservoir computing leverages a fixed, high-dimensional dynamical system to simplify training while excelling in temporal pattern recognition tasks. Distinguishing these methods enhances the development of robust AI systems across robotics, signal processing, and autonomous controls.
Comparison Table
| Aspect | Liquid Neural Networks | Reservoir Computing |
|---|---|---|
| Definition | Adaptive recurrent neural networks mimicking brain fluidity. | Neural networks with fixed recurrent layers and trained readouts. |
| Architecture | Dynamic synapses with time-varying states. | Static random reservoir with readout layer training. |
| Training | Online, local, and continuous adaptation. | Train only output weights, reservoir remains unchanged. |
| Flexibility | Highly flexible for time-series and real-time tasks. | Moderate flexibility; depends on reservoir design. |
| Computational Efficiency | Efficient with adaptive updates; suitable for edge AI. | Simpler training but less adaptive, can be computationally lighter. |
| Applications | Robotics, signal processing, adaptive control systems. | Speech recognition, time-series prediction, nonlinear system modeling. |
| Scalability | Scales well with appropriate hardware acceleration. | Scales based on reservoir size; may require tuning. |
| Key Advantage | Continuous learning with high adaptability. | Simplified training process with robust dynamics. |
Which is better?
Liquid neural networks excel in adapting to dynamic, time-varying inputs through continuous learning and state representation, making them superior for real-time applications and robotics. Reservoir computing offers computational efficiency by using fixed recurrent layers and training only the output, suitable for tasks with stable temporal patterns. The choice depends on application requirements: liquid neural networks provide greater flexibility and adaptability, while reservoir computing favors simplicity and speed.
Connection
Liquid neural networks and reservoir computing both leverage dynamic systems to process time-varying data efficiently, with liquid neural networks using adaptive, continuous-time models inspired by biological neurons. Reservoir computing employs a fixed, high-dimensional dynamical system--called the reservoir--to transform input signals into rich temporal representations, which are then read out by a trained output layer. Both frameworks capitalize on the complex temporal dynamics within their reservoirs to facilitate tasks like speech recognition, time series prediction, and control systems.
Key Terms
Dynamic Systems
Reservoir computing leverages a fixed, high-dimensional dynamical system to project input into a rich feature space, enabling efficient training of output weights for time-dependent tasks. Liquid neural networks employ adaptable, continuous-time neurons with learnable dynamics, providing robust modeling of complex temporal patterns and system adaptability. Explore further to understand their comparative advantages in dynamic systems applications.
Temporal Processing
Reservoir computing leverages fixed, high-dimensional dynamical systems to transform temporal input data into spatial patterns, enabling efficient temporal processing without extensive training of internal weights. Liquid neural networks incorporate continuous-time dynamics with adaptive parameters, providing enhanced flexibility and robustness in modeling complex time-dependent signals. Explore more to understand how these approaches revolutionize temporal data analysis.
Recurrent Architectures
Reservoir computing leverages fixed, random recurrent layers called reservoirs to project input data into a high-dimensional space, simplifying training to only output weights, while liquid neural networks use adaptable recurrent elements that dynamically change states over time for enhanced temporal processing. Both architectures emphasize recurrent connections, but reservoirs maintain static dynamics whereas liquid networks enable continuous state evolution, offering greater flexibility in modeling time-dependent signals. Explore further to understand how these approaches impact efficiency and adaptability in sequential data tasks.
Source and External Links
Reservoir computing - Wikipedia - Reservoir computing is a computational framework using a fixed, high-dimensional, nonlinear dynamical system (the reservoir) to transform input signals, with only a simple readout layer trained for specific tasks.
An introduction to reservoir computing - arXiv - In reservoir computing, input signals drive a nontrainable, high-dimensional nonlinear dynamical system, and only the final readout layer is trained to produce the desired output from the system's state.
Reservoir computing - Reservoir computing devices, such as photonic-inspired edge solutions, leverage this framework for efficient, real-time processing of sequential data like time series, images, and text.