Generative video models create new video content by learning patterns from existing data, enabling tasks like video synthesis and animation. Discriminative video models focus on analyzing and classifying video inputs, often used in tasks such as object detection and activity recognition. Explore the differences and applications of these video modeling techniques to understand their impact on modern technology.
Why it is important
Understanding the difference between Generative video and Discriminative video is crucial for developing effective AI models in computer vision and video analysis. Generative video models create new video content by learning underlying data distributions, enhancing applications like video synthesis and augmentation. Discriminative video models focus on classifying or detecting objects and events within existing videos, improving accuracy in recognition tasks. Knowledge of these distinctions guides researchers and developers in selecting appropriate algorithms to optimize performance and innovation in video technology.
Comparison Table
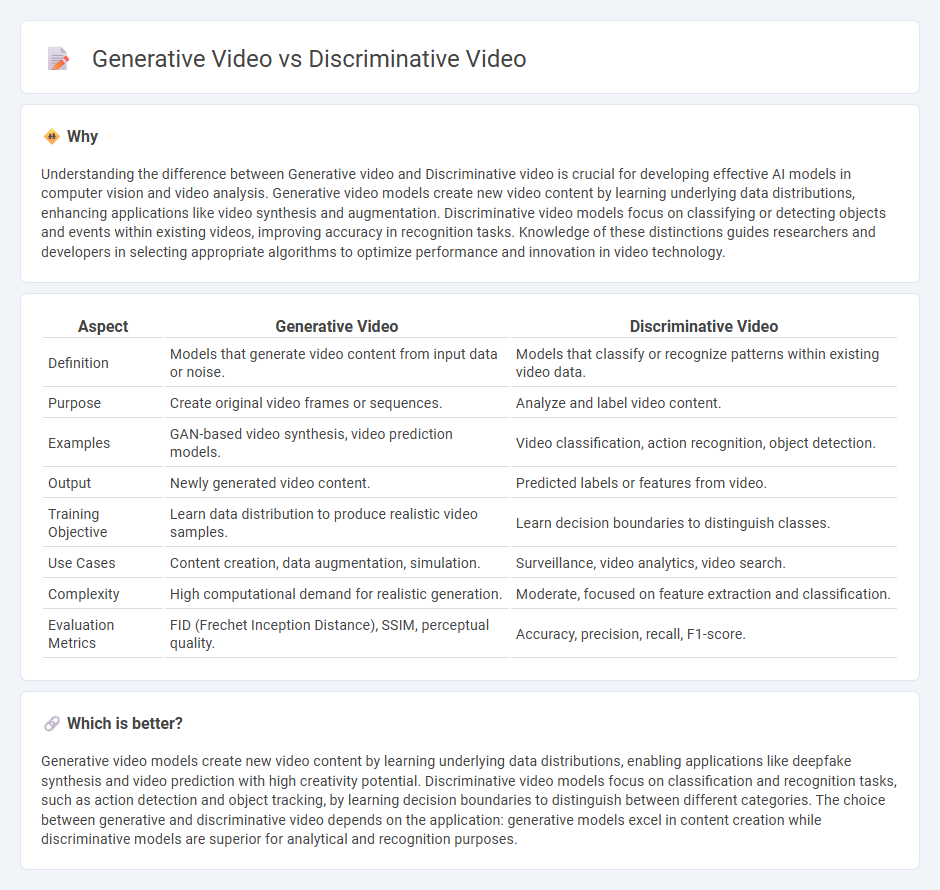
| Aspect | Generative Video | Discriminative Video |
|---|---|---|
| Definition | Models that generate video content from input data or noise. | Models that classify or recognize patterns within existing video data. |
| Purpose | Create original video frames or sequences. | Analyze and label video content. |
| Examples | GAN-based video synthesis, video prediction models. | Video classification, action recognition, object detection. |
| Output | Newly generated video content. | Predicted labels or features from video. |
| Training Objective | Learn data distribution to produce realistic video samples. | Learn decision boundaries to distinguish classes. |
| Use Cases | Content creation, data augmentation, simulation. | Surveillance, video analytics, video search. |
| Complexity | High computational demand for realistic generation. | Moderate, focused on feature extraction and classification. |
| Evaluation Metrics | FID (Frechet Inception Distance), SSIM, perceptual quality. | Accuracy, precision, recall, F1-score. |
Which is better?
Generative video models create new video content by learning underlying data distributions, enabling applications like deepfake synthesis and video prediction with high creativity potential. Discriminative video models focus on classification and recognition tasks, such as action detection and object tracking, by learning decision boundaries to distinguish between different categories. The choice between generative and discriminative video depends on the application: generative models excel in content creation while discriminative models are superior for analytical and recognition purposes.
Connection
Generative video models create realistic video sequences by learning underlying patterns and generating new frames based on input data, while discriminative video models analyze and classify video content by distinguishing between different features or categories. The connection between generative and discriminative video lies in their complementary roles: generative models enhance training datasets for discriminative models by producing synthetic but realistic videos, improving classification accuracy and robustness. Integrating both approaches drives advancements in video understanding, synthesis, and applications like surveillance, content creation, and autonomous systems.
Key Terms
Feature Extraction
Discriminative video models excel in feature extraction by learning to identify distinct patterns directly from labeled training data, enabling precise classification and recognition tasks. Generative video models focus on capturing the underlying data distribution to synthesize realistic video content, often extracting features useful for representation learning and video generation. Explore deeper insights into the comparative strengths of discriminative and generative video feature extraction techniques.
Data Synthesis
Discriminative video models analyze existing video data to classify or detect patterns, relying heavily on labeled datasets for training and accuracy. Generative video models synthesize new video content by learning underlying data distributions, enabling applications such as video prediction, creation, and enhancement through techniques like GANs and VAEs. Explore the advancements and applications of data synthesis in video generation to fully grasp their impact on AI-driven multimedia innovation.
Classification
Discriminative video models excel in classification tasks by learning decision boundaries that differentiate between video categories based on labeled training data, optimizing accuracy in identifying specific actions or objects. Generative video models, while capable of synthesizing realistic video sequences, focus on modeling the joint probability of input features, and their classification ability often relies on extracting features for downstream tasks. Explore deeper insights into the comparative performance and applications of discriminative and generative video models in classification by accessing specialized research and case studies.
Source and External Links
Discriminative Video Representation Learning Using Support Vector Classifiers - Proposes discriminative pooling for video action recognition, using a support vector classifier to identify the most relevant frame features and ignoring irrelevant ones, resulting in improved performance across multiple benchmark datasets.
Deep Discriminative Model for Video Classification - Introduces a deep learning framework that automatically explores discriminative patterns in video data, employs a sparse cubic symmetrical pattern to reduce redundancy, and uses weighted voting for robust classification, achieving superior results compared to state-of-the-art methods.
A Discriminative CNN Video Representation for Event Detection - Develops a discriminative video representation that leverages deep CNNs and improved encoding methods for event detection, outperforming traditional pooling approaches while remaining computationally efficient.