Differential privacy employs mathematical algorithms to add noise to datasets, ensuring individual data points remain indistinguishable while enabling valuable analytics. Data tokenization replaces sensitive information with non-sensitive equivalents called tokens, preserving data usability without exposing original values. Explore how these methods safeguard privacy in modern data security strategies.
Why it is important
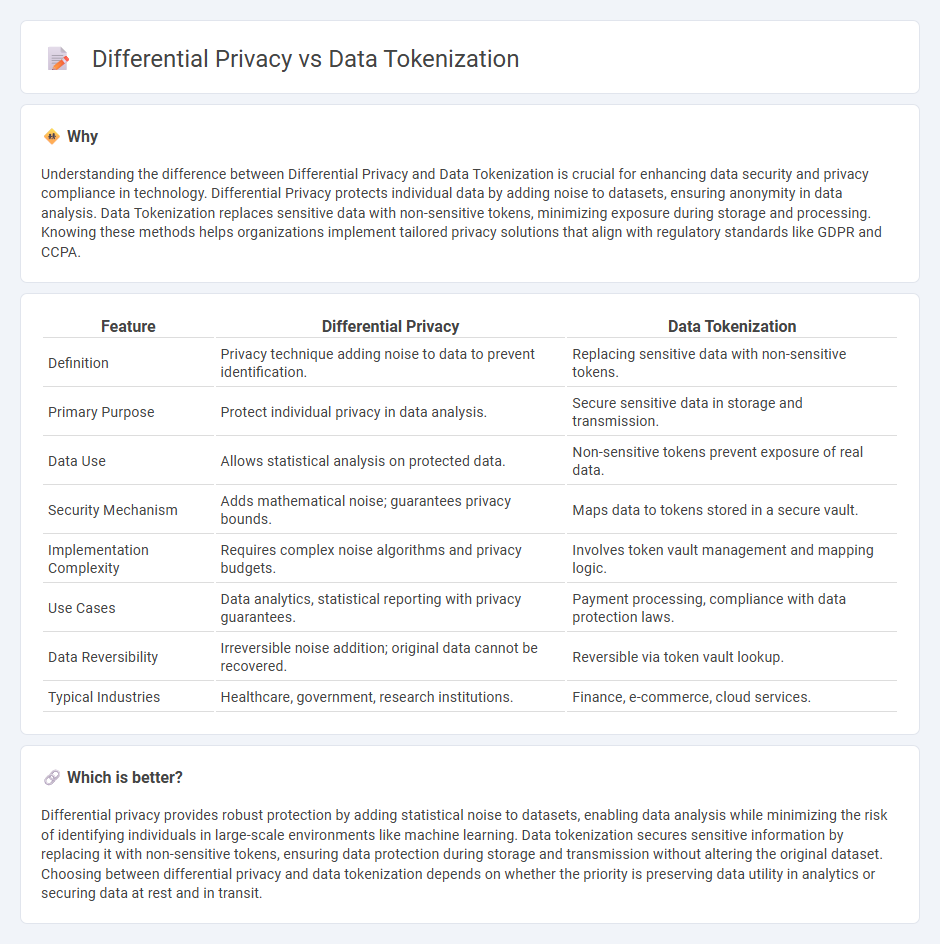
Understanding the difference between Differential Privacy and Data Tokenization is crucial for enhancing data security and privacy compliance in technology. Differential Privacy protects individual data by adding noise to datasets, ensuring anonymity in data analysis. Data Tokenization replaces sensitive data with non-sensitive tokens, minimizing exposure during storage and processing. Knowing these methods helps organizations implement tailored privacy solutions that align with regulatory standards like GDPR and CCPA.
Comparison Table
| Feature | Differential Privacy | Data Tokenization |
|---|---|---|
| Definition | Privacy technique adding noise to data to prevent identification. | Replacing sensitive data with non-sensitive tokens. |
| Primary Purpose | Protect individual privacy in data analysis. | Secure sensitive data in storage and transmission. |
| Data Use | Allows statistical analysis on protected data. | Non-sensitive tokens prevent exposure of real data. |
| Security Mechanism | Adds mathematical noise; guarantees privacy bounds. | Maps data to tokens stored in a secure vault. |
| Implementation Complexity | Requires complex noise algorithms and privacy budgets. | Involves token vault management and mapping logic. |
| Use Cases | Data analytics, statistical reporting with privacy guarantees. | Payment processing, compliance with data protection laws. |
| Data Reversibility | Irreversible noise addition; original data cannot be recovered. | Reversible via token vault lookup. |
| Typical Industries | Healthcare, government, research institutions. | Finance, e-commerce, cloud services. |
Which is better?
Differential privacy provides robust protection by adding statistical noise to datasets, enabling data analysis while minimizing the risk of identifying individuals in large-scale environments like machine learning. Data tokenization secures sensitive information by replacing it with non-sensitive tokens, ensuring data protection during storage and transmission without altering the original dataset. Choosing between differential privacy and data tokenization depends on whether the priority is preserving data utility in analytics or securing data at rest and in transit.
Connection
Differential privacy and data tokenization are interconnected techniques essential for enhancing data security and privacy in technology. Differential privacy introduces mathematical noise to datasets, protecting individual information during analysis, while data tokenization replaces sensitive data elements with non-sensitive equivalents called tokens. Together, these methods minimize the risk of data breaches and unauthorized access by ensuring that personal information remains confidential and unusable to attackers.
Key Terms
Anonymization
Data tokenization replaces sensitive information with unique tokens, effectively anonymizing data by masking original values without altering the data structure, while differential privacy adds statistical noise to datasets, ensuring individual entries cannot be re-identified, thus providing a stronger mathematical privacy guarantee. Tokenization is ideal for data security in applications that need reversible anonymization, whereas differential privacy suits large-scale data analysis with rigorous privacy constraints. Explore further to understand the best anonymization method for your data privacy needs.
Data masking
Data tokenization replaces sensitive data elements with non-sensitive equivalents called tokens, maintaining data format while securing information, which is essential for data masking in compliance with GDPR and HIPAA. Differential privacy introduces random noise to datasets to protect individual identities without altering the data format, enhancing privacy in statistical databases and analytics. Explore the differences and applications of data masking techniques to secure sensitive information effectively.
Noise injection
Data tokenization replaces sensitive information with non-sensitive equivalents called tokens, ensuring original data remains secure without altering its statistical properties. Differential privacy injects controlled noise into datasets or query outputs, effectively masking individual entries while preserving overall data utility. Explore the nuances of noise injection techniques in differential privacy to understand their impact on data protection and accuracy.
Source and External Links
Tokenization (data security) - Wikipedia - Tokenization is the process of replacing sensitive data with a non-sensitive equivalent called a token, which cannot be exploited or reversed without access to the secure tokenization system.
What Is Tokenization? - Akamai - Tokenization protects sensitive information by substituting it with a unique identifier (token) that cannot be used to access the original data without the secure vault where the mapping is stored.
What Is Data Tokenization? Key Concepts and Benefits - Data tokenization is a security method where sensitive data is replaced with unique, non-sensitive tokens, while the original data is stored securely elsewhere, significantly reducing the risk of data breaches.