Edge inference processes data locally on devices such as smartphones or IoT gadgets, dramatically reducing latency and enhancing privacy by minimizing data transmission to central servers. Server-side inference relies on powerful remote servers to analyze data, offering superior computational resources but potentially increasing response time and bandwidth usage. Explore the differences between these approaches to determine the best fit for your application needs.
Why it is important
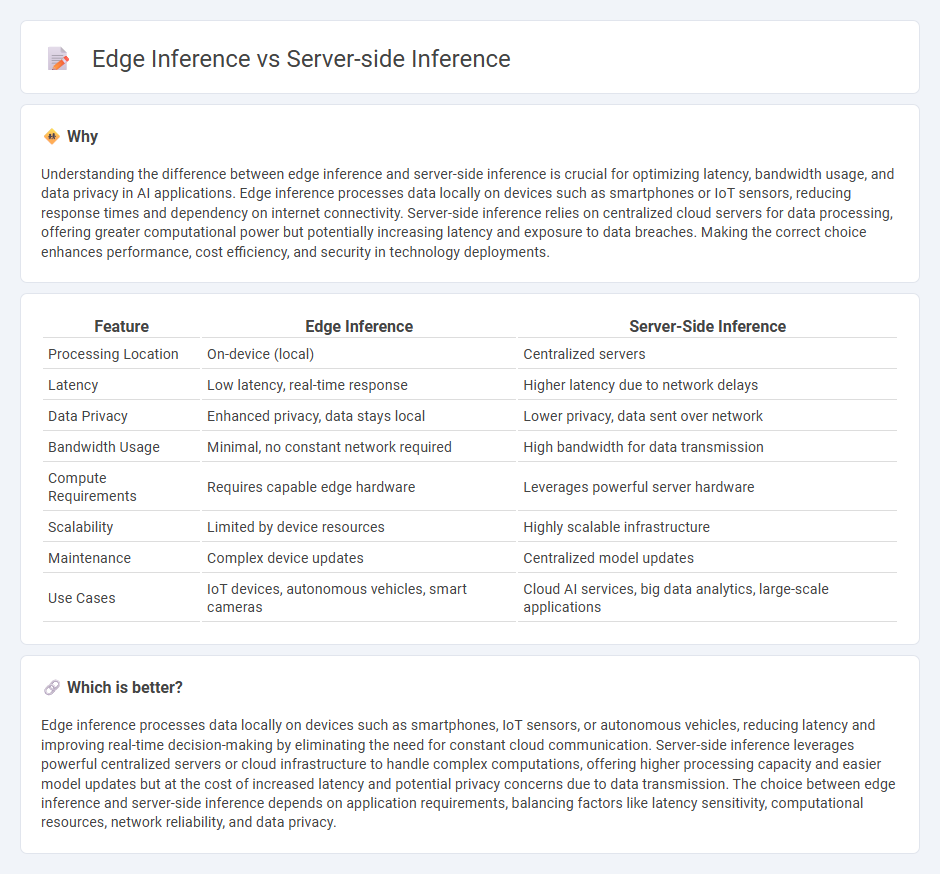
Understanding the difference between edge inference and server-side inference is crucial for optimizing latency, bandwidth usage, and data privacy in AI applications. Edge inference processes data locally on devices such as smartphones or IoT sensors, reducing response times and dependency on internet connectivity. Server-side inference relies on centralized cloud servers for data processing, offering greater computational power but potentially increasing latency and exposure to data breaches. Making the correct choice enhances performance, cost efficiency, and security in technology deployments.
Comparison Table
| Feature | Edge Inference | Server-Side Inference |
|---|---|---|
| Processing Location | On-device (local) | Centralized servers |
| Latency | Low latency, real-time response | Higher latency due to network delays |
| Data Privacy | Enhanced privacy, data stays local | Lower privacy, data sent over network |
| Bandwidth Usage | Minimal, no constant network required | High bandwidth for data transmission |
| Compute Requirements | Requires capable edge hardware | Leverages powerful server hardware |
| Scalability | Limited by device resources | Highly scalable infrastructure |
| Maintenance | Complex device updates | Centralized model updates |
| Use Cases | IoT devices, autonomous vehicles, smart cameras | Cloud AI services, big data analytics, large-scale applications |
Which is better?
Edge inference processes data locally on devices such as smartphones, IoT sensors, or autonomous vehicles, reducing latency and improving real-time decision-making by eliminating the need for constant cloud communication. Server-side inference leverages powerful centralized servers or cloud infrastructure to handle complex computations, offering higher processing capacity and easier model updates but at the cost of increased latency and potential privacy concerns due to data transmission. The choice between edge inference and server-side inference depends on application requirements, balancing factors like latency sensitivity, computational resources, network reliability, and data privacy.
Connection
Edge inference processes data locally on devices like IoT sensors and smartphones, reducing latency and bandwidth usage while enabling real-time decision-making. Server-side inference involves sending data to centralized cloud servers for complex analysis, leveraging powerful hardware and large-scale models. Together, they form a hybrid AI architecture where edge inference handles immediate, low-latency tasks and server-side inference performs intensive model computation, enhancing overall system efficiency and scalability.
Key Terms
Latency
Server-side inference typically experiences higher latency due to data transmission to and from centralized cloud data centers, resulting in delays especially under heavy network loads or distant servers. Edge inference reduces latency significantly by processing data locally on devices like IoT sensors or smartphones, enabling real-time responses crucial for applications such as autonomous vehicles and augmented reality. Discover how optimizing inference strategies can enhance performance in your AI deployments.
Scalability
Server-side inference leverages centralized cloud infrastructure, providing high scalability through robust computational resources and easy integration with extensive datasets. Edge inference processes data locally on devices, reducing latency but facing scalability limits due to hardware constraints and distributed management challenges. Explore the detailed scalability trade-offs between server-side and edge inference to optimize your AI deployment strategy.
Data privacy
Server-side inference processes data on centralized cloud servers, which can expose sensitive information to potential breaches during transmission and storage, raising significant data privacy concerns. Edge inference executes computations directly on local devices, minimizing data transfer and reducing exposure to external threats, thus enhancing privacy protection for user data. Explore deeper insights into how edge inference advances data privacy standards in modern AI applications.
Source and External Links
Server-side batching: Scaling inference throughput in machine ... - Server-side inference allows on-demand batching of requests to maximize throughput, enabling responsive (though not strictly realtime) predictions for applications like video-based object detection.
What is inference? - TitanML - An inference server is specialized software that manages and executes AI model predictions in production, acting as the bridge between trained models and real-world applications.
Triton Inference Server - Triton Inference Server is an open source platform for deploying and serving AI models from multiple frameworks, optimized for performance across cloud, edge, and embedded devices.