Self-supervised learning leverages large amounts of unlabeled data by generating labels from the data itself, enabling models to learn useful representations without manual annotation. Semi-supervised learning combines a small set of labeled data with a larger pool of unlabeled data to improve model accuracy while reducing the dependency on extensive labeled datasets. Explore the differences and applications of these innovative learning paradigms to enhance your understanding of advanced machine learning techniques.
Why it is important
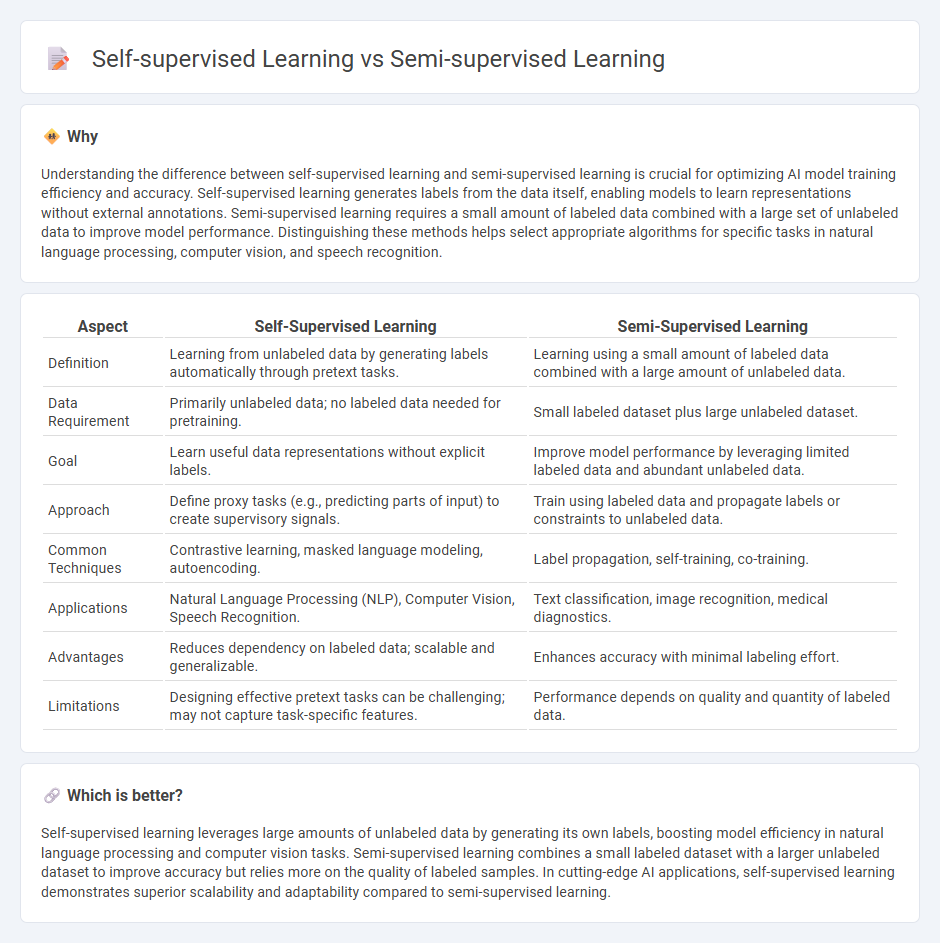
Understanding the difference between self-supervised learning and semi-supervised learning is crucial for optimizing AI model training efficiency and accuracy. Self-supervised learning generates labels from the data itself, enabling models to learn representations without external annotations. Semi-supervised learning requires a small amount of labeled data combined with a large set of unlabeled data to improve model performance. Distinguishing these methods helps select appropriate algorithms for specific tasks in natural language processing, computer vision, and speech recognition.
Comparison Table
| Aspect | Self-Supervised Learning | Semi-Supervised Learning |
|---|---|---|
| Definition | Learning from unlabeled data by generating labels automatically through pretext tasks. | Learning using a small amount of labeled data combined with a large amount of unlabeled data. |
| Data Requirement | Primarily unlabeled data; no labeled data needed for pretraining. | Small labeled dataset plus large unlabeled dataset. |
| Goal | Learn useful data representations without explicit labels. | Improve model performance by leveraging limited labeled data and abundant unlabeled data. |
| Approach | Define proxy tasks (e.g., predicting parts of input) to create supervisory signals. | Train using labeled data and propagate labels or constraints to unlabeled data. |
| Common Techniques | Contrastive learning, masked language modeling, autoencoding. | Label propagation, self-training, co-training. |
| Applications | Natural Language Processing (NLP), Computer Vision, Speech Recognition. | Text classification, image recognition, medical diagnostics. |
| Advantages | Reduces dependency on labeled data; scalable and generalizable. | Enhances accuracy with minimal labeling effort. |
| Limitations | Designing effective pretext tasks can be challenging; may not capture task-specific features. | Performance depends on quality and quantity of labeled data. |
Which is better?
Self-supervised learning leverages large amounts of unlabeled data by generating its own labels, boosting model efficiency in natural language processing and computer vision tasks. Semi-supervised learning combines a small labeled dataset with a larger unlabeled dataset to improve accuracy but relies more on the quality of labeled samples. In cutting-edge AI applications, self-supervised learning demonstrates superior scalability and adaptability compared to semi-supervised learning.
Connection
Self-supervised learning generates supervisory signals from unlabeled data by predicting parts of the input, enabling models to learn useful representations without explicit labels. Semi-supervised learning combines a small amount of labeled data with large amounts of unlabeled data, leveraging the representations learned through self-supervised methods to improve classification accuracy. Both approaches reduce reliance on labeled datasets, enhancing model performance in scenarios with limited annotated data.
Key Terms
Labeled data
Semi-supervised learning leverages a small amount of labeled data combined with a larger set of unlabeled data to improve model accuracy, making it suitable for scenarios where labeling is costly. Self-supervised learning, however, generates labels internally from the data itself, eliminating the need for manual labeling and enabling robust feature extraction from vast unlabeled datasets. Explore further to understand how these methods optimize labeled data utilization in machine learning.
Unlabeled data
Semi-supervised learning leverages a small amount of labeled data alongside a large volume of unlabeled data to improve model performance, often using techniques like consistency regularization and pseudo-labeling. Self-supervised learning, by contrast, generates its own supervisory signals from the unlabeled data itself through pretext tasks such as contrastive learning and generative modeling, enabling the model to learn useful representations without any labeled instances. Explore the latest advancements in how these approaches utilize unlabeled data to maximize learning efficiency.
Representation learning
Semi-supervised learning leverages both labeled and unlabeled data to enhance representation learning by utilizing limited annotations to guide the model's feature extraction process. Self-supervised learning relies solely on unlabeled data, creating pretext tasks that enable the model to learn robust and generalizable representations without external labels. Explore deeper insights and practical applications of these techniques to advance your understanding of state-of-the-art representation learning strategies.
Source and External Links
What Is Semi-Supervised Learning? - IBM - Semi-supervised learning combines labeled and unlabeled data to train AI models, especially useful when labeled data is scarce or expensive to obtain but unlabeled data is abundant.
Semi-Supervised Learning Explained - Oracle - This machine learning approach first trains a model on a small labeled dataset, then leverages a larger pool of unlabeled data to improve model performance.
Weak supervision - Wikipedia - Weak supervision, or semi-supervised learning, uses a small set of human-labeled data and a large amount of unlabeled data, making it practical when full labeling is costly or infeasible.