Differential privacy ensures the protection of individual data by adding controlled noise to datasets, preventing identification of personal information during analysis. Federated learning enables decentralized model training by allowing multiple devices to collaboratively learn a shared prediction model while keeping the raw data localized on individual devices. Explore the differences and applications of these two cutting-edge techniques to better understand their roles in advancing data privacy and machine learning.
Why it is important
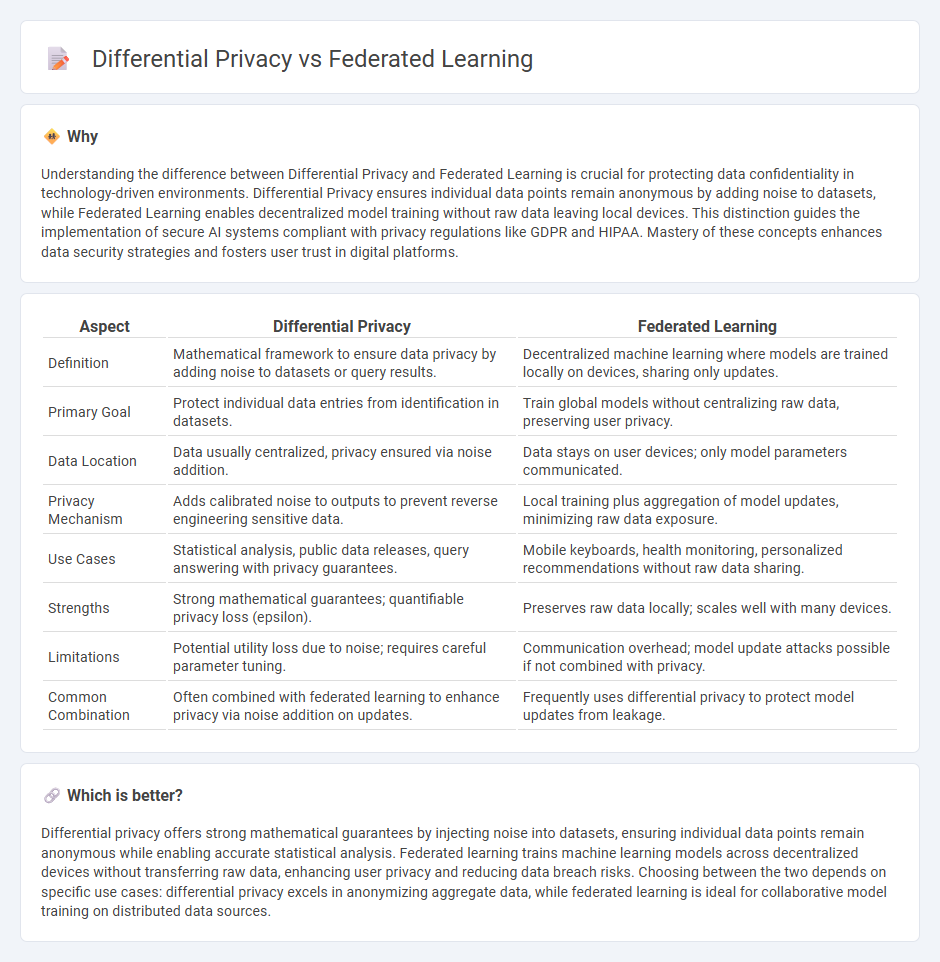
Understanding the difference between Differential Privacy and Federated Learning is crucial for protecting data confidentiality in technology-driven environments. Differential Privacy ensures individual data points remain anonymous by adding noise to datasets, while Federated Learning enables decentralized model training without raw data leaving local devices. This distinction guides the implementation of secure AI systems compliant with privacy regulations like GDPR and HIPAA. Mastery of these concepts enhances data security strategies and fosters user trust in digital platforms.
Comparison Table
| Aspect | Differential Privacy | Federated Learning |
|---|---|---|
| Definition | Mathematical framework to ensure data privacy by adding noise to datasets or query results. | Decentralized machine learning where models are trained locally on devices, sharing only updates. |
| Primary Goal | Protect individual data entries from identification in datasets. | Train global models without centralizing raw data, preserving user privacy. |
| Data Location | Data usually centralized, privacy ensured via noise addition. | Data stays on user devices; only model parameters communicated. |
| Privacy Mechanism | Adds calibrated noise to outputs to prevent reverse engineering sensitive data. | Local training plus aggregation of model updates, minimizing raw data exposure. |
| Use Cases | Statistical analysis, public data releases, query answering with privacy guarantees. | Mobile keyboards, health monitoring, personalized recommendations without raw data sharing. |
| Strengths | Strong mathematical guarantees; quantifiable privacy loss (epsilon). | Preserves raw data locally; scales well with many devices. |
| Limitations | Potential utility loss due to noise; requires careful parameter tuning. | Communication overhead; model update attacks possible if not combined with privacy. |
| Common Combination | Often combined with federated learning to enhance privacy via noise addition on updates. | Frequently uses differential privacy to protect model updates from leakage. |
Which is better?
Differential privacy offers strong mathematical guarantees by injecting noise into datasets, ensuring individual data points remain anonymous while enabling accurate statistical analysis. Federated learning trains machine learning models across decentralized devices without transferring raw data, enhancing user privacy and reducing data breach risks. Choosing between the two depends on specific use cases: differential privacy excels in anonymizing aggregate data, while federated learning is ideal for collaborative model training on distributed data sources.
Connection
Differential privacy enhances federated learning by ensuring that individual data contributions remain confidential while aggregating model updates across decentralized devices. Federated learning enables decentralized model training without centralizing raw data, thus relying on differential privacy techniques to protect user information from potential inference attacks. Combining these methods optimizes data privacy in distributed machine learning systems, making technology solutions more secure and compliant with privacy regulations.
Key Terms
Data decentralization
Federated learning enables data decentralization by allowing multiple devices or servers to collaboratively train a machine learning model without sharing raw data, thereby enhancing privacy. Differential privacy protects individual data by injecting noise into the data or queries, but it typically operates on centralized data collections or aggregated results. Explore the nuances between these privacy-preserving techniques and their impact on decentralized data environments.
Privacy-preserving algorithms
Federated learning enables decentralized model training by keeping data localized on user devices, significantly reducing data exposure risks. Differential privacy injects controlled noise into datasets or query results, ensuring individual data points cannot be reverse-engineered from aggregate outputs. Explore the strengths and applications of these privacy-preserving algorithms to understand their impact on secure machine learning.
Model aggregation
Federated learning enables decentralized model training by aggregating locally computed updates from multiple devices, enhancing data privacy without centralizing raw data. Differential privacy introduces noise to model updates or aggregation results to prevent leakage of individual data points during the aggregation process. Explore how combining federated learning and differential privacy strategies optimizes secure model aggregation for privacy-preserving AI.
Source and External Links
What Is Federated Learning? | IBM - Federated learning is a decentralized approach to training machine learning models, preserving data privacy by keeping sensitive information on local devices.
A Step-by-Step Guide to Federated Learning in Computer Vision - Federated learning provides a decentralized approach to training machine learning models, offering benefits such as privacy protection and access to heterogeneous data.
Federated learning - Federated learning is a machine learning technique that trains models on local datasets without explicitly exchanging data, aiming to create a shared global model.